About¶
Tsdat is a data pipeline written in Python for standardizing time-series datasets.
It was originally written for use in the Marine Energy community and was developed with data standards and best practices borrowed from the ARM program, but the library and framework itself is applicable to any domain in which large datasets are collected.
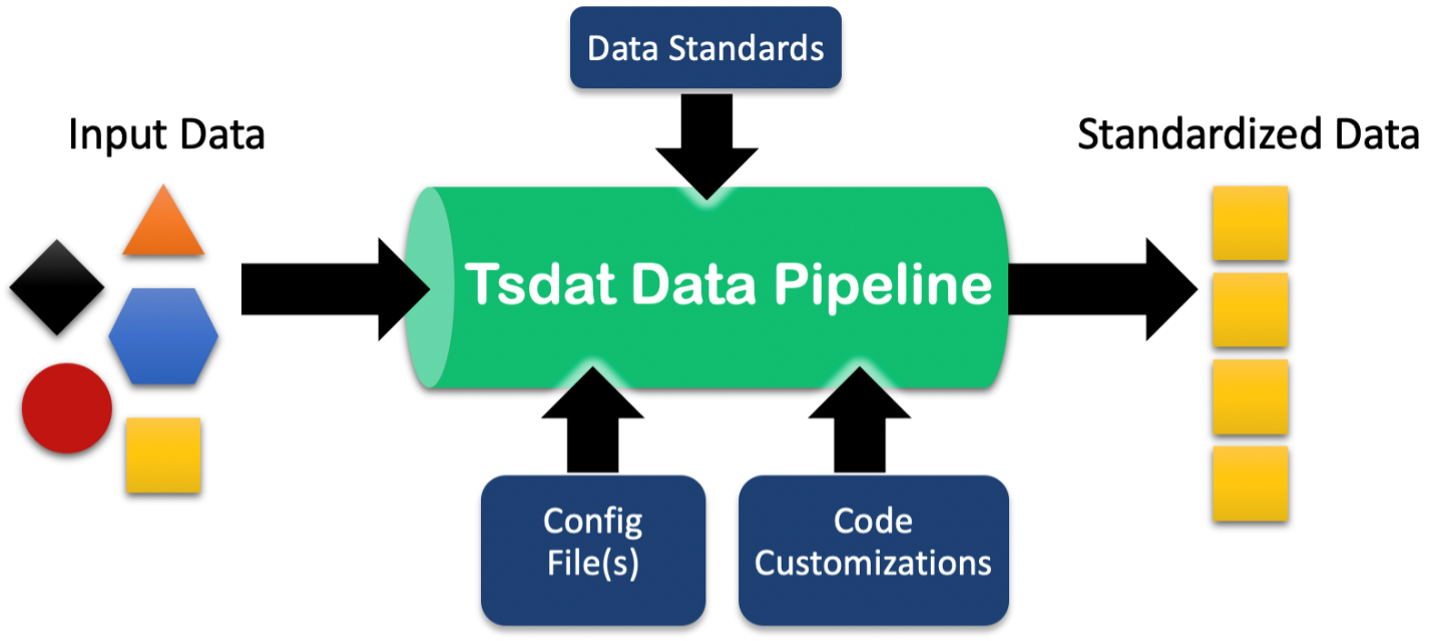
Framework for data ingestion and standardization.¶
How It Works¶
Tsdat is built to be completely customizable by the user.
A raw datafile is first read into the pipeline by a built-in or user-defined file handler. Output from the filehandler is then organized/standardized through user-defined yaml configuration files, where variable names and metadata are specified. Data can then be run through quality control functions built into Tsdat, which are also specified in the yaml configuration files. From thence, data can be output in the format of the user’s choosing.
In addition, further customization for more complicated or multi-dimensional datasets can be accomplished using user-defined code “hooks” (functions) that are triggered at various points in the pipeline. Plots can be added through a particular “hook” as well.
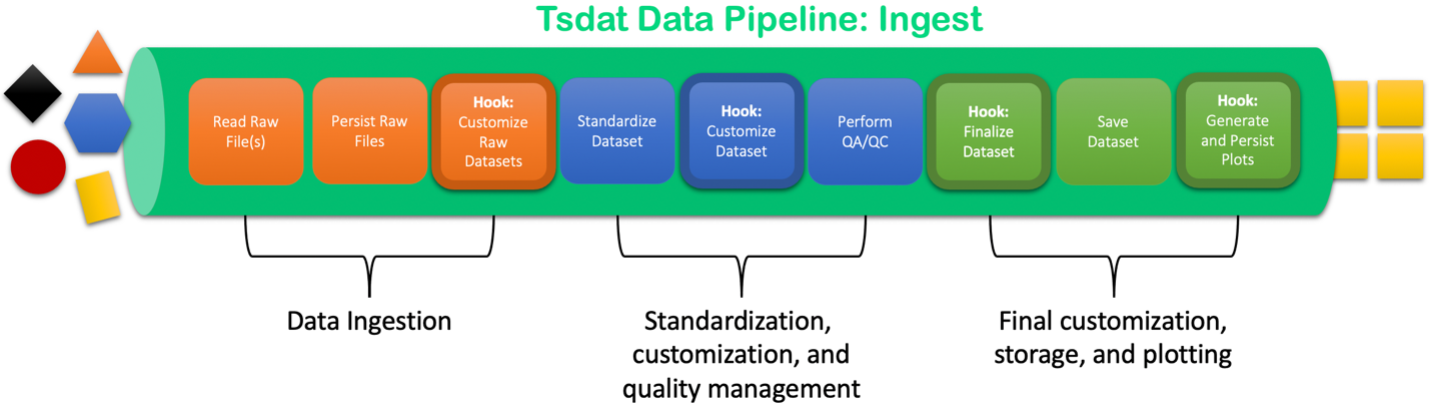
Overview of a Tsdat Data Ingestion Pipeline.¶
Tsdat’s pipeline framework is built on top of xarray and the netCDF file format, which is frequently used in the climate science community. The netCDF format is particularly powerful because it provides a two-level data structure that stores independent, multi-dimensional variables by shared dimensions (e.g. latitude, longitude, and time). It is highly recommended to familiarize oneself with this package and file format first.
To quickly summarize, data is handled in xarray DataArrays combined into a single Dataset with attributes, or info about the data. Xarray can be thought of as a multidimensional extension of pandas, though it is not built on top of pandas. Datasets and DataArrays support all of the same basic functionality of dictionaries (e.g., indexing, iterating, etc.), with additional functionality that is designed to streamline the process of analyzing and working with data.
Motivation¶
Publically available datasets are often difficult to use because the information needed to understand the data are buried away in technical reports and loose documentation that are often difficult to access and are not well-maintained. Even when you are able to get your hands on both the dataset and the metadata you need to understand the data, it can still be tricky to write code that reads each data file and handles edge cases. Additionally, as you process more and more datasets it can become cumbersome to keep track of and maintain all of the code you have written to process each of these datasets.
The goal of tsdat is to produce high-quality datasets that are much more accessible to data users. Tsdat encourages following data standards and best practices when building data pipelines so that your data is clean, easy to understand, more accessible, and ultimately more valuable to your data users.