Tsdat¶
tsdat is an open-source Python framework that makes creating pipelines to process and standardize time-series data more easy,clear, and quick to stand up so that you can spend less time data-wrangling and more time data- investigating.
Quick Overview¶
Tsdat is a python library for standardizing time-series datasets. It uses yaml configuration files to specify the variable names and metadata that will be produced by tsdat data pipelines.
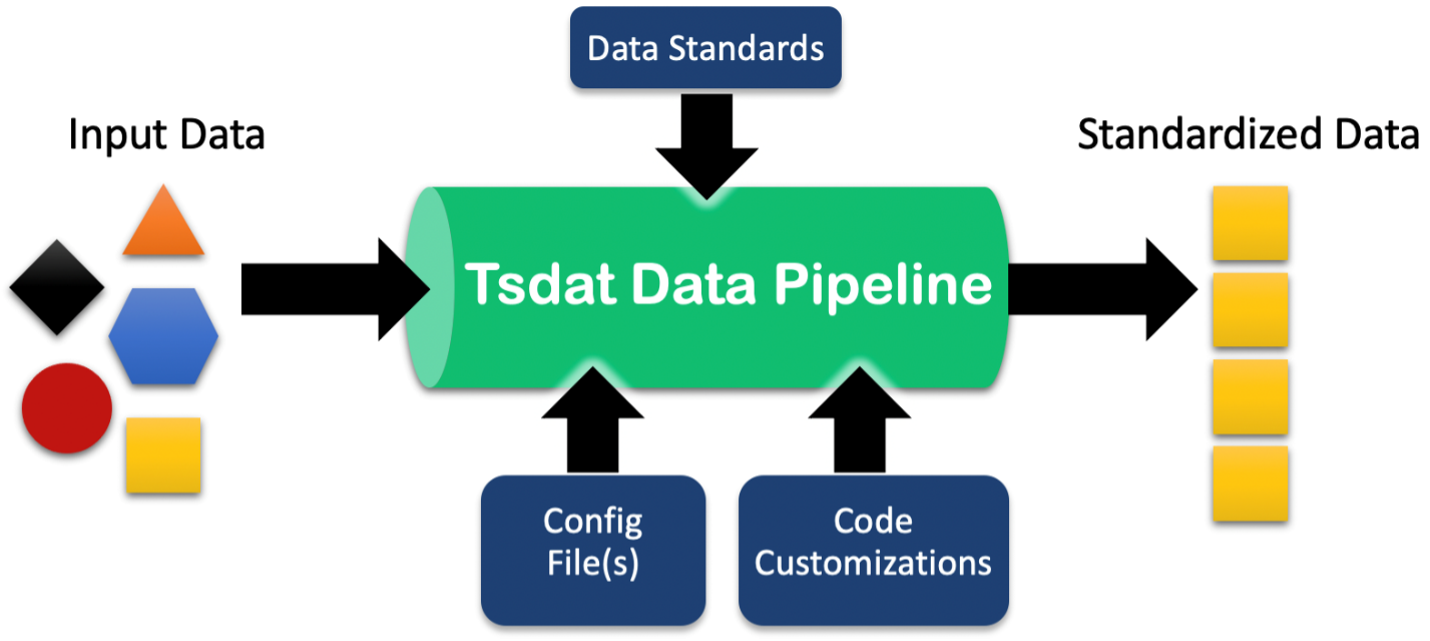
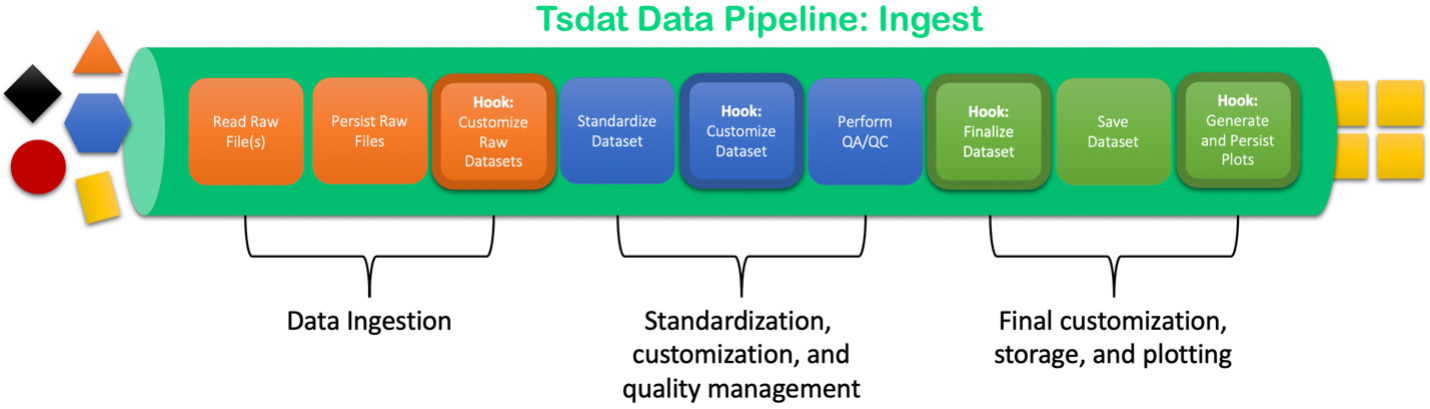
Tsdat data pipelines are primarily customizable through the aforementioned configuration files and also through user-defined code “hooks” that are triggered at various points in the pipeline.
Tsdat is built on top of Xarray and the netCDF file format frequently used in the Climate Science community. Tsdat was originally written for use in the Marine Energy community and was developed with data standards and best practices borrowed from the ARM program, but the library and framework itself is applicable to any domain in which large datasets are collected.
Motivation¶
Too many datasets are difficult to use because the information needed to understand the data are buried away in technical reports and loose documentation that are often difficult to access and are not well-maintained. Even when you are able to get your hands on both the dataset and the metadata you need to understand the data, it can still be tricky to write code that reads each data file and handles edge cases. Additionally, as you process more and more datasets it can become cumbersome to keep track of and maintain all of the code you have written to process each of these datasets.
Wouldn’t it just be much easier if all the data you worked with was in the same file format and had the same file structure? Wouldn’t it take less time to learn about the dataset if each data file also contained the metadata you needed in order to conduct your analysis? Wouldn’t it be nice if the data you worked with had been checked for quality and values that were suspect or bad had been flagged? That would all be great, right? This is the goal of tsdat, an open-source python library that aims to make it easier to produce high-quality datasets that are much more accessible to data users. Tsdat encourages following data standards and best practices when building data pipelines so that your data is clean, easy to understand, more accessible, and ultimately more valuable to your data users.