Configuring Tsdat¶
Tsdat pipelines can be configured to tailor the specific data and metadata that will be contained in the standardized dataset. Tsdat pipelines provide multiple layers of configuration to allow the community to easily contribute common functionality (such as unit converters or file readers), to provide a low intial barrier of entry for basic ingests, and to allow full customization of the pipeline for very unique circumstances. The following figure illustrates the different phases of the pipeline along with multiple layers of configuration that Tsdat provides.
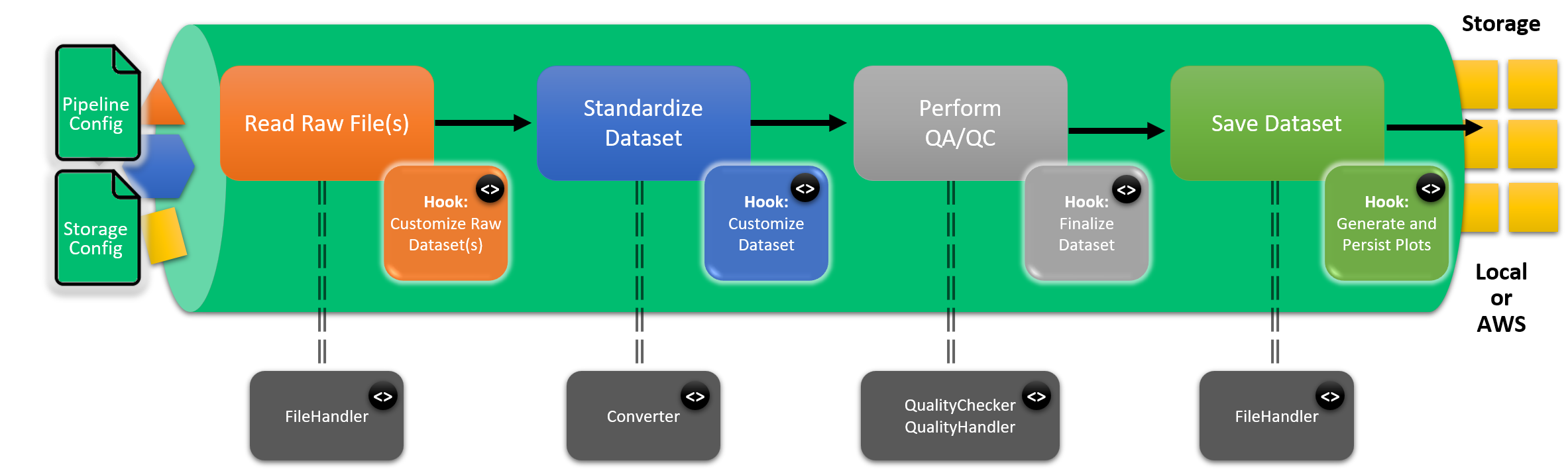
As shown in the figure, users can customize Tsdat in three ways:
Configuration files - shown as input to the pipeline on the left
Code hooks - indicated inside the pipeline with code (<>) bubbles. Code hooks are provided by extending the IngestPipeline base class to create custom pipeline behavior.
Helper classes - indicated outside the pipeline with code (<>) bubbles. Helper classes are described in more detail below and provide reusable, cross-pipeline functionality such as custom file readers or quality control checks. The specific helper classes that are used for a given pipeline are declared in the storage or pipeline config files.
More information on config file syntax and code hook base classes are provided below.
Note
Tsdat pipelines produce standardized datasets that follow the conventions and terminology provided in the Data Standards Document. Please refer to this document for more detailed information about the format of standardized datasets.
Configuration Files¶
Configuration files provide an explict, declarative way to define and customize the behavior of tsdat data pipelines. There are two types of configuration files:
Storage config
Pipeline config
This section breaks down the various properties of both types of configuration files and shows how these files can be modified to support a wide variety of data pipelines.
Note
Config files are written in yaml format. We recommend using an IDE with yaml support (such as VSCode) for editing your config files.
Note
In addition to your pre-configured pipeline template, see the tsdat examples folder for more configuration examples.
Note
In your pipeline template project, configuration files can be found in the config/ folder.
Storage Config¶
The storage config file specifies which Storage class will be used to save processed data, declares configuration properties for that Storage (such as the root folder), and declares various FileHandler classses that will be used to read/write data with the specified file extensions.
Currently there are two provided storage classes:
FilesystemStorage - saves to local filesystem
AwsStorage - saves to an AWS bucket (requires an AWS account with admin priviledges)
Each storage class has different configuration parameters, but they both share a common file_handlers section as explained below.
Note
Environment variables can be referenced in the storage config file using ${PARAMETER}
syntax in the yaml. Any referenced environment variables need to be set via the shell or via
the os.environ dictionary from your run_pipeline.py file.
The CONFIG_DIR environment parameter set automatically by tsdat and refers to the folder where
the storage config file is located.
FilesystemStorage Parameters¶
storage:
classname: tsdat.io.FilesystemStorage # Choose from FilesystemStorage or AwsStorage
parameters:
retain_input_files: True # Whether to keep input files after they are processed
root_dir: ${CONFIG_DIR}/../storage/root # The root dir where processed files will be stored
AwsStorage Parameters¶
storage:
classname: tsdat.io.AwsStorage # Choose from FilesystemStorage or AwsStorage
parameters:
retain_input_files: True # Whether to keep input files after they are processed
bucket_name: tsdat_test # The name of the AWS S3 bucket where processed files will be stored
root_dir: /storage/root # The root dir (key) prefix for all processed files created in the bucket
File Handlers¶
File Handlers declare the classes that should be used to read input and output files. Correspondingly, the file_handlers section in the yaml is split into two parts for input and output. For input files, you can specify a Python regular expression to match any specific file name pattern that should be read by that File Handler.
For output files, you can specify one or more formats. Tsdat will write processed data files using all the output formats specified. We recommend using the NetCdfHandler as this is the most powerful and flexible format that will support any data. However, other file formats may also be used such as Parquet or CSV. More output file handlers will be added over time.
file_handlers:
input:
sta: # This is a label to identify your file handler
file_pattern: '.*\.sta' # Use a Python regex to identify files this handler should process
classname: pipeline.filehandlers.StaFileHandler # Declare the fully qualified name of the handler class
output:
netcdf: # This is a label to identify your file handler
file_extension: '.nc' # Declare the file extension to use when writing output files
classname: tsdat.io.filehandlers.NetCdfHandler # Declare the fully qualified name of the handler class
Pipeline Config¶
The pipeline config file is used to define how the pipeline will standardize input data. It defines all the pieces of your standardized dataset, as described in the in the Data Standards Document. Specifically, it identifies the following components:
Global attributes - dataset metadata
Dimensions - shape of data
Coordinate variables - coordinate values for a specific dimension
Data variables - all other variables in the dataset
Quality management - quality tests to be performed for each variable and any associated corrections to be applied for failing tests.
Each pipeline template will include a starter pipeline config file in the config folder. It will work out of the box, but the configuration should be tweaked according to the specifics of your dataset.
A full annotated example of an ingest pipeline config file is provided below and can also be referenced in the Tsdat Repository
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 258 259 260 261 262 263 264 265 266 267 268 269 270 271 272 273 274 275 276 277 278 279 280 281 282 283 284 285 286 287 288 289 290 291 292 293 294 295 296 297 298 299 300 301 302 303 304 305 306 307 308 309 310 311 312 313 314 315 316 317 318 319 320 321 322 323 324 325 326 327 328 329 330 331 332 333 334 335 336 337 338 339 340 341 342 343 344 345 346 347 348 349 350 351 352 353 354 355 356 357 358 359 360 361 362 363 364 365 366 367 368 369 370 371 372 373 374 375 376 377 378 379 380 381 382 383 384 385 386 387 388 389 390 391 392 393 394 395 396 397 398 399 400 401 402 403 404 405 406 407 408 409 410 411 412 413 414 415 416 417 418 419 420 421 422 423 424 425 426 427 428 429 430 431 432 433 434 435 436 437 438 439 440 441 442 443 444 445 446 447 448 449 450 451 452 453 454 455 456 457 458 459 460 461 462 463 464 465 466 467 468 469 470 471 472 473 474 475 476 477 478 479 480 481 482 483 484 485 486 487 488 489 490 491 492 493 494 495 496 497 498 499 500 501 502 503 504 505 506 507 508 509 510 511 512 513 514 515 516 517 518 519 520 521 522 523 524 525 526 527 528 529 530 531 532 533 534 535 536 537 538 539 540 541 542 543 544 545 546 547 548 549 550 551 552 553 554 555 556 557 558 559 560 561 562 563 564 565 566 567 568 569 570 571 572 573 574 575 576 577 578 579 580 581 582 583 584 585 586 587 588 589 590 591 592 593 594 595 596 597 598 599 600 601 602 603 604 605 606 607 608 609 610 611 612 613 614 615 616 617 618 619 620 621 622 623 624 625 626 627 628 629 630 631 632 633 634 635 636 637 638 639 640 641 642 643 644 645 646 647 648 649 650 651 652 653 654 655 656 657 658 659 660 661 662 663 664 | ####################################################################
# TSDAT (Time-Series Data) INGEST PIPELINE CONFIGURATION TEMPLATE
#
# This file contains an annotated example of how to configure an
# tsdat data ingest processing pipeline.
####################################################################
# Specify the type of pipeline that will be run: Ingest or VAP
#
# Ingests are run against raw data and are used to convert
# proprietary instrument data files into standardized format, perform
# quality control checks against the data, and apply corrections as
# needed.
#
# VAPs are used to combine one or more lower-level standardized data
# files, optionally transform data to new coordinate grids, and/or
# to apply scientific algorithms to derive new variables that provide
# additional insights on the data.
pipeline:
type: "Ingest"
# Used to specify the level of data that this pipeline will use as
# input. For ingests, this will be used as the data level for raw data.
# If type: Ingest is specified, this defaults to "00"
# input_data_level: "00"
# Used to specify the level of data that this pipeline will produce.
# It is recommended that ingests use "a1" and VAPs should use "b1",
# but this is not enforced.
data_level: "a1"
# A label for the location where the data were obtained from
location_id: "humboldt_z05"
# A string consisting of any letters, digits, "-" or "_" that can
# be used to uniquely identify the instrument used to produce
# the data. To prevent confusion with the temporal resolution
# of the instrument, the instrument identifier must not end
# with a number.
dataset_name: "buoy"
# An optional qualifier that distinguishes these data from other
# data sets produced by the same instrument. The qualifier
# must not end with a number.
#qualifier: "lidar"
# A optional description of the data temporal resolution
# (e.g., 30m, 1h, 200ms, 14d, 10Hz). All temporal resolution
# descriptors require a units identifier.
#temporal: "10m"
####################################################################
# PART 1: DATASET DEFINITION
# Define dimensions, variables, and metadata that will be included
# in your processed, standardized data file.
####################################################################
dataset_definition:
#-----------------------------------------------------------------
# Global Attributes (general metadata)
#
# All optional attributes are commented out. You may remove them
# if not applicable to your data.
#
# You may add any additional attributes as needed to describe your
# data collection and processing activities.
#-----------------------------------------------------------------
attributes:
# A succinct English language description of what is in the dataset.
# The value would be similar to a publication title.
# Example: "Atmospheric Radiation Measurement (ARM) program Best
# Estimate cloud and radiation measurements (ARMBECLDRAD)"
# This attribute is highly recommended but is not required.
title: "Buoy Dataset for Buoy #120"
# Longer English language description of the data.
# Example: "ARM best estimate hourly averaged QC controlled product,
# derived from ARM observational Value-Added Product data: ARSCL,
# MWRRET, QCRAD, TSI, and satellite; see input_files for the names of
# original files used in calculation of this product"
# This attribute is highly recommended but is not required.
description: "Example ingest dataset used for demonstration purposes."
# The version of the standards document this data conforms to.
# This attribute is highly recommended but is not required.
# conventions: "ME Data Pipeline Standards: Version 1.0"
# If an optional Digital Object Identifier (DOI) has been obtained
# for the data, it may be included here.
#doi: "10.21947/1671051"
# The institution who produced the data
# institution: "Pacific Northwest National Laboratory"
# Include the url to the specific tagged release of the code
# used for this pipeline invocation.
# Example, https://github.com/clansing/twrmr/releases/tag/1.0.
# Note that MHKiT-Cloud will automatically create a new code
# release whenever the pipeline is deployed to production and
# record this attribute automatically.
code_url: "https://github.com/tsdat/tsdat/releases/tag/v0.2.2"
# Published or web-based references that describe the methods
# algorithms, or third party libraries used to process the data.
#references: "https://github.com/MHKiT-Software/MHKiT-Python"
# A more detailed description of the site location.
#location_meaning: "Buoy is located of the coast of Humboldt, CA"
# Name of instrument(s) used to collect data.
#instrument_name: "Wind Sentinel"
# Serial number of instrument(s) used to collect data.
#serial_number: "000011312"
# Description of instrument(s) used to collect data.
#instrument_meaning: "Self-powered floating buoy hosting a suite of meteorological and marine instruments."
# Manufacturer of instrument(s) used to collect data.
#instrument_manufacturer: "AXYS Technologies Inc."
# The date(s) of the last time the instrument(s) was calibrated.
#last_calibration_date: "2020-10-01"
# The expected sampling interval of the instrument (e.g., "400 us")
#sampling_interval: "10 min"
#-----------------------------------------------------------------
# Dimensions (shape)
#-----------------------------------------------------------------
dimensions:
# All time series data must have a "time" dimension
# TODO: provide a link to the documentation online
time:
length: "unlimited"
#-----------------------------------------------------------------
# Variable Defaults
#
# Variable defaults can be used to specify a default dimension(s),
# data type, or variable attributes. This can be used to reduce the
# number of properties that a variable needs to define in this
# config file, which can be useful for vaps or ingests with many
# variables.
#
# Once a default property has been defined, (e.g. 'type: float64')
# that property becomes optional for all variables (e.g. No variables
# need to have a 'type' property).
#
# This section is entirely optional, so it is commented out.
#-----------------------------------------------------------------
# variable_defaults:
# Optionally specify defaults for variable inputs. These defaults will
# only be applied to variables that have an 'input' property. This
# is to allow for variables that are created on the fly, but defined in
# the config file.
# input:
# If this is specified, the pipeline will attempt to match the file pattern
# to an input filename. This is useful for cases where a variable has the
# same name in multiple input files, but it should only be retrieved from
# one file.
# file_pattern: "buoy"
# Specify this to indicate that the variable must be retrieved. If this is
# set to True and the variable is not found in the input file the pipeline
# will crash. If this is set to False, the pipeline will continue.
# required: True
# Defaults for the converter used to translate input numpy arrays to
# numpy arrays used for calculations
# converter:
#-------------------------------------------------------------
# Specify the classname of the converter to use as a default.
# A converter is used to convert the raw data into standardized
# values.
#
# Use the DefaultConverter for all non-time variables that
# use units supported by udunits2.
# https://www.unidata.ucar.edu/software/udunits/udunits-2.2.28/udunits2.html#Database
#
# If your raw data has units that are not supported by udunits2,
# you can specify your own Converter class.
#-------------------------------------------------------------
# classname: "tsdat.utils.converters.DefaultConverter"
# If the default converter always requires specific parameters, these
# can be defined here. Note that these parameters are not tied to the
# classname specified above and will be passed to all converters defined
# here.
# parameters:
# Example of parameter format:
# param_name: param_value
# The name(s) of the dimension(s) that dimension this data by
# default. For time-series tabular data, the following is a 'good'
# default to use:
# dims: [time]
# The data type to use by default. The data type must be one of:
# int8 (or byte), uint8 (or ubyte), int16 (or short), uint16 (or ushort),
# int32 (or int), uint32 (or uint), int64 (or long), uint64 (or ulong),
# float32 (or float), float64 (or double), char, str
# type: float64
# Any attributes that should be defined by default
# attrs:
# Default _FillValue to use for missing data. Recommended to use
# -9999 because it is the default _FillValue according to CF
# conventions for netCDF data.
# _FillValue: -9999
#-----------------------------------------------------------------
# Variables
#-----------------------------------------------------------------
variables:
#---------------------------------------------------------------
# All time series data must have a "time" coordinate variable which
# contains the data values for the time dimension
# TODO: provide a link to the documentation online
#---------------------------------------------------------------
time: # Variable name as it will appear in the processed data
#---------------------------------------------------------------
# The input section for each variable is used to specify the
# mapping between the raw data file and the processed output data
#---------------------------------------------------------------
input:
# Name of the variable in the raw data
name: "DataTimeStamp"
#-------------------------------------------------------------
# A converter is used to convert the raw data into standardized
# values.
#-------------------------------------------------------------
# Use the StringTimeConverter if your raw data provides time
# as a formatted string.
converter:
classname: "tsdat.utils.converters.StringTimeConverter"
parameters:
# A list of timezones can be found here:
# https://en.wikipedia.org/wiki/List_of_tz_database_time_zones
timezone: "US/Pacific"
time_format: "%Y-%m-%d %H:%M:%S"
# Use the TimestampTimeConverter if your raw data provides time
# as a numeric UTC timestamp
#converter:
# classname: tsdat.utils.converters.TimestampTimeConverter
# parameters:
# # Unit of the numeric value as used by pandas.to_datetime (D,s,ms,us,ns)
# unit: s
# The shape of this variable. All coordinate variables (e.g., time) must
# have a single dimension that exactly matches the variable name
dims: [time]
# The data type of the variable. Must be one of:
# int8 (or byte), uint8 (or ubyte), int16 (or short), uint16 (or ushort),
# int32 (or int), uint32 (or uint), int64 (or long), uint64 (or ulong),
# float32 (or float), float64 (or double), char, str
type: int64
#-------------------------------------------------------------
# The attrs section define the attributes (metadata) that will
# be set for this variable.
#
# All optional attributes are commented out. You may remove them
# if not applicable to your data.
#
# You may add any additional attributes as needed to describe your
# variables.
#
# Any metadata used for QC tests will be indicated.
#-------------------------------------------------------------
attrs:
# A minimal description of what the variable represents.
long_name: "Time offset from epoch"
# A string exactly matching a value in from the CF or MRE
# Standard Name table, if a match exists
#standard_name: time
# A CFUnits-compatible string indicating the units the data
# are measured in.
# https://cfconventions.org/Data/cf-conventions/cf-conventions-1.8/cf-conventions.html#units
#
# Note: CF Standards require this exact format for time.
# UTC is strongly recommended.
# https://cfconventions.org/Data/cf-conventions/cf-conventions-1.8/cf-conventions.html#time-coordinate
units: "seconds since 1970-01-01T00:00:00"
#-----------------------------------------------------------------
# Mean temperature variable (non-coordinate variable)
#-----------------------------------------------------------------
sea_surface_temperature: # Variable name as it will appear in the processed data
#---------------------------------------------------------------
# The input section for each variable is used to specify the
# mapping between the raw data file and the processed output data
#---------------------------------------------------------------
input:
# Name of the variable in the raw data
name: "Surface Temperature (C)"
# Units of the variable in the raw data
units: "degC"
# The shape of this variable
dims: [time]
# The data type of the variable. Can be one of:
# [byte, ubyte, char, short, ushort, int32 (or int), uint32 (or uint),
# int64 (or long), uint64 (or ulong), float, double, string]
type: double
#-------------------------------------------------------------
# The attrs section define the attributes (metadata) that will
# be set for this variable.
#
# All optional attributes are commented out. You may remove them
# if not applicable to your data.
#
# You may add any additional attributes as needed to describe your
# variables.
#
# Any metadata used for QC tests will be indicated.
#-------------------------------------------------------------
attrs:
# A minimal description of what the variable represents.
long_name: "Mean sea surface temperature"
# An optional attribute to provide human-readable context for what this variable
# represents, how it was measured, or anything else that would be relevant to end-users.
#comment: Rolling 10-minute average sea surface temperature. Aligned such that the temperature reported at time 'n' represents the average across the interval (n-1, n].
# A CFUnits-compatible string indicating the units the data
# are measured in.
# https://cfconventions.org/Data/cf-conventions/cf-conventions-1.8/cf-conventions.html#units
units: "degC"
# The value used to initialize the variable’s data. Defaults to -9999.
# Coordinate variables must not use this attribute.
#_FillValue: -9999
# An array of variable names that depend on the values from this variable. This is primarily
# used to indicate if a variable has an ancillary qc variable.
# NOTE: QC ancillary variables will be automatically recorded via the MHKiT-Cloud pipeline engine.
#ancillary_variables: []
# A two-element array of [min, max] representing the smallest and largest valid values
# of a variable. Values outside valid_range will be filled with _FillValue.
#valid_range: [-50, 50]
# The maximum allowed difference between any two consecutive values of a variable,
# values outside of which should be flagged as "Bad".
# This attribute is used for the valid_delta QC test. If not specified, this
# variable will be omitted from the test.
#valid_delta: 0.25
# A two-element array of [min, max] outside of which the data should be flagged as "Bad".
# This attribute is used for the fail_min and fail_max QC tests.
# If not specified, this variable will be omitted from these tests.
#fail_range: [0, 40]
# A two-element array of [min, max] outside of which the data should be flagged as "Indeterminate".
# This attribute is used for the warn_min and warn_max QC tests.
# If not specified, this variable will be omitted from these tests.
#warn_range: [0, 30]
# An array of strings indicating what corrections, if any, have been applied to the data.
#corrections_applied: []
# The height of the instrument above ground level (AGL), or in the case of above
# water, above the surface.
#sensor_height: "30m"
#-----------------------------------------------------------------
# Example of a variables that hold a single scalar value that
# is not present in the raw data.
#-----------------------------------------------------------------
latitude:
data: 71.323 #<-----The data field can be used to specify a pre-set value
type: float
#<-----This variable has no input, which means it will be set by
# the pipeline and not pulled from the raw data
#<-----This variable has no dimensions, which means it will be
# a scalar value
attrs:
long_name: "North latitude"
standard_name: "latitude"
comment: "Recorded lattitude at the instrument location"
units: "degree_N"
valid_range: [-90.f, 90.f]
longitude:
data: -156.609
type: float
attrs:
long_name: "East longitude"
standard_name: "longitude"
comment: "Recorded longitude at the instrument location"
units: "degree_E"
valid_range: [-180.f, 180.f]
#-----------------------------------------------------------------
# Example of a variable that is derived by the processing pipeline
#-----------------------------------------------------------------
foo:
type: float
#<-----This variable has no input, which means it will be set by
# the pipeline and not pulled from the raw data
dims: [time]
attrs:
long_name: "some other property"
units: "kg/m^3"
comment: "Computed from temp_mean point value using some formula..."
references: ["http://sccoos.org/data/autoss/", "http://sccoos.org/about/dmac/"]
---
####################################################################
# PART 2: QC TESTS
# Define the QC tests that will be applied to variable data.
####################################################################
coordinate_variable_qc_tests:
#-----------------------------------------------------------------
# The following section defines the default qc tests that will be
# performed on coordinate variables in a dataset. Note that by
# default, coordinate variable tests will NOT set a QC bit and
# will trigger a critical pipeline failure. This is because
# Problems with coordinate variables are considered to cause
# the dataset to be unusable and should be manually reviewed.
#
# However, the user may override the default coordinate variable
# tests and error handlers if they feel that data correction is
# warranted.
#
# For a complete list of tests provided by MHKiT-Cloud, please see
# the tsdat.qc.operators package.
#
# Users are also free to add custom tests defined by their own
# checker classes.
#-----------------------------------------------------------------
quality_management:
#-----------------------------------------------------------------
# The following section defines the default qc tests that will be
# performed on variables in a dataset.
#
# For a complete list of tests provided by MHKiT-Cloud, please see
# the tsdat.qc.operators package.
#
# Users are also free to add custom tests defined by their own
# checker classes.
#-----------------------------------------------------------------
#-----------------------------------------------------------------
# Checks on coordinate variables
#-----------------------------------------------------------------
# The name of the test.
manage_missing_coordinates:
# Quality checker used to identify problematic variable values.
# Users can define their own quality checkers and link them here
checker:
# This quality checker will identify values that are missing,
# NaN, or equal to each variable's _FillValue
classname: "tsdat.qc.operators.CheckMissing"
# Quality handler used to manage problematic variable values.
# Users can define their own quality handlers and link them here.
handlers:
# This quality handler will cause the pipeline to fail
- classname: "tsdat.qc.error_handlers.FailPipeline"
# Which variables to apply the test to
variables:
# keyword to apply test to all coordinate variables
- COORDS
manage_coordinate_monotonicity:
checker:
# This quality checker will identify variables that are not
# strictly monotonic (That is, it identifies variables whose
# values are not strictly increasing or strictly decreasing)
classname: "tsdat.qc.operators.CheckMonotonic"
handlers:
- classname: "tsdat.qc.error_handlers.FailPipeline"
variables:
- COORDS
#-----------------------------------------------------------------
# Checks on data variables
#-----------------------------------------------------------------
manage_missing_values:
# The class that performs the quality check. Users are free
# to override with their own class if they want to change
# behavior.
checker:
classname: "tsdat.qc.operators.CheckMissing"
# Error handlers are optional and run after the test is
# performed if any of the values fail the test. Users
# may specify one or more error handlers which will be
# executed in sequence. Users are free to add their
# own QCErrorHandler subclass if they want to add custom
# behavior.
handlers:
# This error handler will replace any NaNs with _FillValue
- classname: "tsdat.qc.error_handlers.RemoveFailedValues"
# Quality handlers and all other objects that have a 'classname'
# property can take a dictionary of parameters. These
# parameters are made available to the object or class in the
# code and can be used to implement custom behavior with little
# overhead.
parameters:
# The correction parameter is used by the RemoveFailedValues
# quality handler to append to a list of corrections for each
# variable that this handler is applied to. As a best practice,
# quality handlers that modify data values should use the
# correction parameter to update the 'corrections_applied'
# variable attribute on the variable this test is applied to.
correction: "Set NaN and missing values to _FillValue"
# This quality handler will record the results of the
# quality check in the ancillary qc variable for each
# variable this quality manager is applied to.
- classname: "tsdat.qc.error_handlers.RecordQualityResults"
parameters:
# The bit (1-32) used to record the results of this test.
# This is used to update the variable's ancillary qc
# variable.
bit: 1
# The assessment of the test. Must be either 'Bad' or 'Indeterminate'
assessment: "Bad"
# The description of the data quality from this check
meaning: "Value is equal to _FillValue or NaN"
variables:
# keyword to apply test to all non-coordinate variables
- DATA_VARS
manage_fail_min:
checker:
classname: "tsdat.qc.operators.CheckFailMin"
handlers:
- classname: "tsdat.qc.error_handlers.RecordQualityResults"
parameters:
bit: 2
assessment: "Bad"
meaning: "Value is less than the fail_range."
variables:
- DATA_VARS
manage_fail_max:
checker:
classname: "tsdat.qc.operators.CheckFailMax"
handlers:
- classname: "tsdat.qc.error_handlers.RecordQualityResults"
parameters:
bit: 3
assessment: "Bad"
meaning: "Value is greater than the fail_range."
variables:
- DATA_VARS
manage_warn_min:
checker:
classname: "tsdat.qc.operators.CheckWarnMin"
handlers:
- classname: "tsdat.qc.error_handlers.RecordQualityResults"
parameters:
bit: 4
assessment: "Indeterminate"
meaning: "Value is less than the warn_range."
variables:
- DATA_VARS
manage_warn_max:
checker:
classname: "tsdat.qc.operators.CheckWarnMax"
handlers:
- classname: "tsdat.qc.error_handlers.RecordQualityResults"
parameters:
bit: 5
assessment: "Indeterminate"
meaning: "Value is greater than the warn_range."
variables:
- DATA_VARS
manage_valid_delta:
checker:
classname: "tsdat.qc.operators.CheckValidDelta"
parameters:
dim: time # specifies the dimension over which to compute the delta
handlers:
- classname: "tsdat.qc.error_handlers.RecordQualityResults"
parameters:
bit: 6
assessment: "Indeterminate"
meaning: "Difference between current and previous values exceeds valid_delta."
variables:
- DATA_VARS
#-----------------------------------------------------------------
# Example of a user-created test that shows how to specify
# an error handler. Error handlers may be optionally added to
# any of the tests described above. (Note that this example will
# not work, it is just provided as an example of adding a
# custom QC test.)
#-----------------------------------------------------------------
# temp_test:
# checker:
# classname: "myproject.qc.operators.TestTemp"
# #-------------------------------------------------------------
# # See the tsdat.qc.error_handlers package for a list of
# # available error handlers.
# #-------------------------------------------------------------
# handlers:
# # This handler will set bit number 7 on the ancillary qc
# # variable for the variable(s) this test applies to.
# - classname: "tsdat.qc.error_handlers.RecordQualityResults"
# parameters:
# bit: 7
# assessment: "Indeterminate"
# meaning: "Test for some special condition in temperature."
# # This error handler will notify users via email. The
# # datastream name, variable, and failing values will be
# # included.
# - classname: "tsdat.qc.error_handlers.SendEmailAWS"
# parameters:
# message: "Test failed..."
# recipients: ["carina.lansing@pnnl.gov", "maxwell.levin@pnnl.gov"]
# # Specifies the variable(s) this quality manager applies to
# variables:
# - temp_mean
|
Code Customizations¶
This section describes all the types of classes that can be extended in Tsdat to provide
custom pipeline behavior. To start with, each pipeline will define a main Pipeline class
which is used to run the pipeline itself. Each pipeline template will come with a Pipeline
class pre-defined in the pipeline/pipeline.py file. The Pipeline class extends a specific base class depending upon the
template that was selected. Currently, we only support one pipeline base class, tsdat.pipeline.ingest_pipeline.IngestPipeline.
Later, support for VAP pipelines will be added. Each pipeline base class provides certain abstract methods which
the developer can override if desired to customize pipeline functionality. In your template repository,
your Pipeline class will come with all the hook methods stubbed out automatically (i.e., they will be
included with an empty definition). Later as more templates are added - in particular to support
specific data models- hook methods may be pre-filled out to implement prescribed calculations.
In addition to your Pipeline class, additional classes can be defined to provide specific behavior such as unit conversions, quality control tests, or reading/writing files. This section lists all of the custom classes that can be defined in Tsdat and what their purpose is.
Note
For more information on classes in Python, see https://docs.python.org/3/tutorial/classes.html
Note
We warmly encourage the community to contribute additional support classes such as FileHandlers and QCCheckers.
IngestPipeline Code Hooks¶
The following hook methods (which can be easily identified because they all start with the ‘hook_’ prefix) are provided in the IngestPipeline template. They are listed in the order that they are executed in the pipeline.
- hook_customize_raw_datasets
Hook to allow for user customizations to one or more raw xarray Datasets before they merged and used to create the standardized dataset. This method would typically only be used if the user is combining multiple files into a single dataset. In this case, this method may be used to correct coordinates if they don’t match for all the files, or to change variable (column) names if two files have the same name for a variable, but they are two distinct variables.
This method can also be used to check for unique conditions in the raw data that should cause a pipeline failure if they are not met.
This method is called before the inputs are merged and converted to standard format as specified by the config file.
- hook_customize_dataset
Hook to allow for user customizations to the standardized dataset such as inserting a derived variable based on other variables in the dataset. This method is called immediately after the apply_corrections hook and before any QC tests are applied.
- hook_finalize_dataset
Hook to apply any final customizations to the dataset before it is saved. This hook is called after quality tests have been applied.
- hook_generate_and_persist_plots
Hook to allow users to create plots from the xarray dataset after processing and QC have been applied and just before the dataset is saved to disk.
File Handlers¶
File Handlers are classes that are used to read and write files. Each File Handler
should extend the tsdat.io.filehandlers.file_handlers.AbstractFileHandler base
class. The AbstractFileHandler base class defines two methods:
- read
Read a file into an XArray Dataset object.
- write
Write an XArray Dataset to file. This method only needs to be implemented for handlers that will be used to save processed data to persistent storage.
Each pipeline template comes with a default custom FileHandler implementation to use as an example if needed. In addition, see the ImuFileHandler for another example of writing a custom FileHandler to read raw instrument data.
The File Handlers that are to be used in your pipeline are configured in your storage config file
Converters¶
Converters are classes that are used to convert units from the raw data to standardized format.
Each Converter should extend the tsdat.utils.converters.Converter base class.
The Converter base class defines one method, run, which converts a numpy ndarray of variable
data from the input units to the output units. Currently tsdat provides two converters for working
with time data. tsdat.utils.converters.StringTimeConverter converts time values in a variety
of string formats, and tsdat.utils.converters.TimestampTimeConverter converts time values in
long integer format. In addtion, tsdat provides a tsdat.utils.converters.DefaultConverter
which converts any units from one udunits2 supported units type to another.
Quality Management¶
Two types of classes can be defined in your pipeline to ensure standardized data meets quality requirements:
- QualityChecker
Each QualityChecker performs a specific QC test on one or more variables in your dataset.
- QualityHandler
Each QualityHandler can be specified to run if a particular QC test fails. It can be used to correct invalid values, such as interpolating to fill gaps in the data.
The specific QCCheckers and QCHandlers used for a pipeline and the variables they run on are specified in the pipeline config file.
Quality Checkers¶
Quality Checkers are classes that are used to perform a QC test on a specific
variable. Each Quality Checker should extend the tsdat.qc.checkers.QualityChecker base
class, which defines a run() method that performs the check.
Each QualityChecker defined in the pipeline config file will be automatically initialized
by the pipeline and invoked on the specified variables. See the API Reference
for a detailed description of the QualityChecker.run() method as well as a list of all
QualityCheckers defined by Tsdat.
Quality Handlers¶
Quality Handlers are classes that are used to correct variable data when a specific
quality test fails. An example is interpolating missing values to fill gaps.
Each Quality Handler should extend the tsdat.qc.handlers.QualityHandler base
class, which defines a run() method that performs the correction.
Each QualityHandler defined in the pipeline config file will be automatically initialized
by the pipeline and invoked on the specified variables. See the API Reference
for a detailed description of the QualityHandler.run() method as well as a list of all
QualityHandlers defined by Tsdat.